

Perplexity citeert per antwoord gemiddeld 3 tot 4 bronnen. Die plekken verdelen zich over het hele internet, en welke pagina's daarvoor in aanmerking komen hangt af van factoren die fundamenteel anders werken dan bij Google. Als jouw site er structureel niet bij zit, mis je een platform met 100 miljoen maandelijkse gebruikers dat met 239% groeide in minder dan een jaar.
Dit artikel gaat over hoe Perplexity's selectiealgoritme werkt, wat de meeste sites verkeerd doen en wat je concreet kunt veranderen. Geen aannames over jouw situatie: gebruik de stappen hier om te meten waar je staat, want de cijfers over het gemiddelde zijn duidelijk genoeg om serieus te nemen.
- Versheid bepaalt 44,2% van Perplexity's bronkeuze, meer dan domeinautoriteit als losse factor (SE Ranking, 216.524 pagina's)
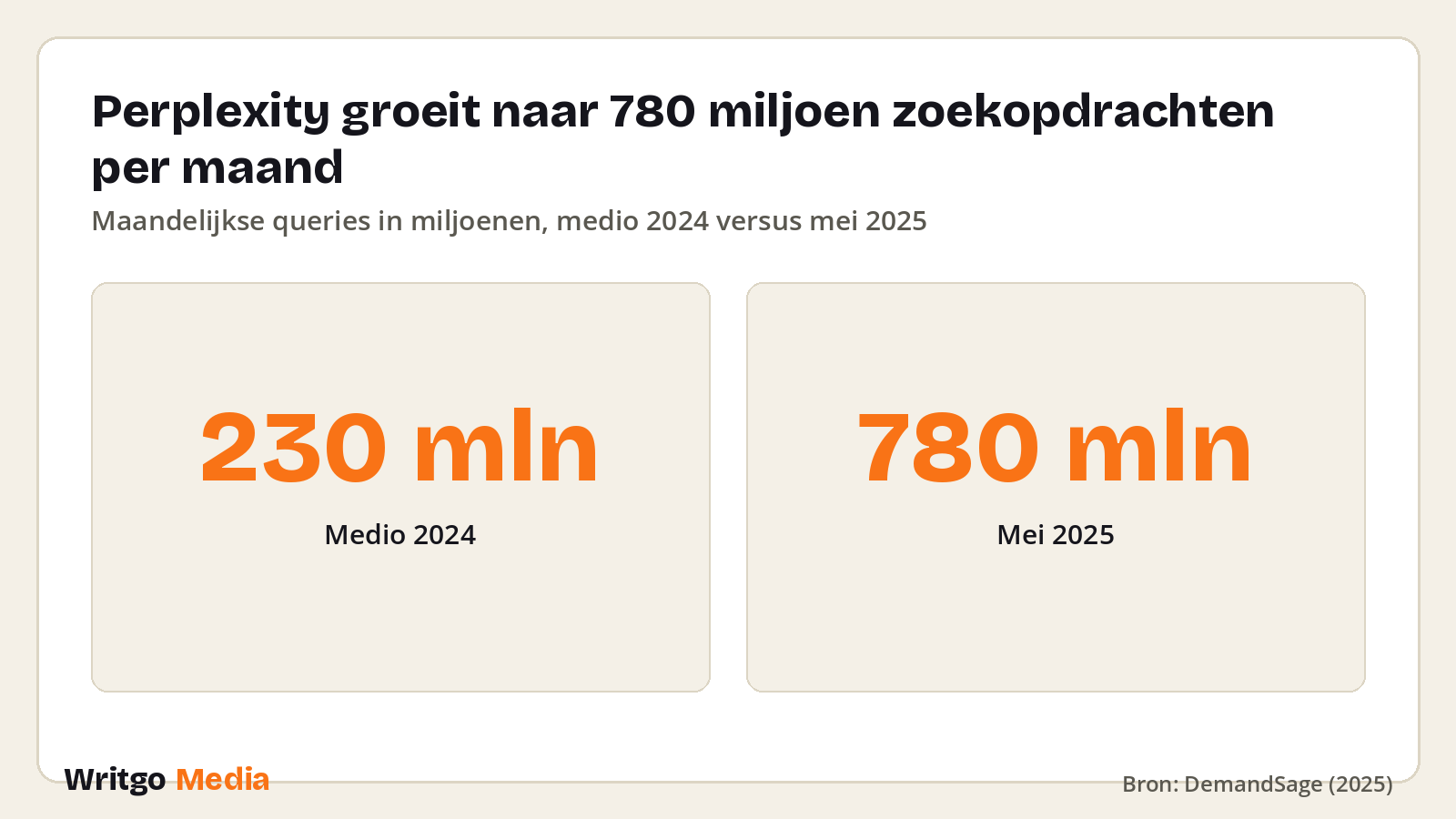
- Perplexity verwerkte in mei 2025 al 780 miljoen zoekopdrachten per maand, tegen 230 miljoen in medio 2024
- Slechts 7% van de 500 populairste Nederlandse sites heeft een llms.txt, blijkt uit eigen Writgo-onderzoek
- LinkedIn steeg tussen november 2025 en februari 2026 van buiten de top 20 naar de meest geciteerde bron voor professionele vragen
- Perplexity werd in 2025 betrapt op het omzeilen van robots.txt via vermomd crawlerverkeer
Perplexity is geen zoekmachine, het is een antwoordmachine
Google toont tien links. Perplexity geeft één antwoord, samengesteld uit 3 tot 4 geciteerde bronnen die rechtsboven in het scherm staan met doorkliklinks. In plaats van om een klikpositie strijdt je om een citatieplek, en dat zijn twee heel verschillende dingen om op te optimaliseren.
De schaal maakt dat urgent. In mei 2025 verwerkte Perplexity volgens DemandSage 780 miljoen zoekopdrachten per maand, tegenover 230 miljoen in medio 2024. Dat is een stijging van 239% in minder dan een jaar. In april 2026 meldde het bedrijf 100 miljoen maandelijkse gebruikers over al zijn producten samen.
Perplexity werkt via retrieval-augmented generation (RAG): het doorzoekt het web in real time, selecteert relevante pagina's en laat een taalmodel een samenvatting schrijven met expliciete bronvermeldingen. Wie geciteerd wordt, is zichtbaar op precies het moment dat een gebruiker een vraag stelt, niet ergens op pagina 1 van resultaten die niemand verder scrolt.
Dat verschil in mechanic maakt Perplexity interessant naast andere AI-zoekmachines: het is geen chatbot die raadt, het is een bronverwijzer die expliciet verantwoording aflegt. Voor ondernemers die serieus zijn over AI-vindbaarheid, is dat het meest controleerbare platform van dit moment.
Hoe Perplexity bronnen selecteert, en waarom dat verrast
Achter elke Perplexity-zoekopdracht gaat een drielaags rankingproces schuil. Het systeem haalt eerst kandidaatpagina's op via een eigen webindex, herrangschikt ze op relevantie en kwaliteit, en filtert ze daarna door een zogeheten L3 XGBoost quality gate die pagina's uitsluit die niet voldoen aan drempels voor entiteitsduidelijkheid en gezaghebbendheid. Pas wat overblijft, wordt geciteerd.
Welke factor telt het zwaarst? Versheid. Een analyse van 216.524 pagina's door SE Ranking laat zien dat temporele versheid 44,2% van het selectiealgoritme bepaalt. Dat is meer dan domeinautoriteit, structured data en platformaanwezigheid bij elkaar als losse factoren. Voor wie gewend is aan Google-SEO, is dit een omgekeerde wereld.
Domeinautoriteit weegt mee voor ongeveer 15%, maar Perplexity meet dat anders dan Google. Het systeem werkt met zogeheten trust seeds: platforms die het als betrouwbaar herkent. Denk aan LinkedIn, Reddit, Wikipedia, Crunchbase en overheidswebsites. Wie op die platformen actief en vindbaar is, heeft een structureel voordeel dat los staat van de sterkte van het eigen domein.
Per onderwerp hanteert Perplexity bovendien handmatige domeinboosts. Inhoud over technologie, AI en wetenschap krijgt een positieve multiplier, zo documenteerde Nick Lafferty; sport- en entertainmentcontent wordt juist gesupprimeerd. Doe je iets met software, SaaS of digitale dienstverlening, dan sta je al aan de goede kant van dat filter.
Waarom de publicatiedatum soms meer doet dan je hele domein
Dat versheid verantwoordelijk is voor 44,2% van de bronkeuze klinkt logisch tot je beseft wat dat praktisch betekent: een goed artikel van twee jaar oud op een sterk domein verliest het van een matig artikel van vorige maand op een onbekende site. Niet altijd, maar genoeg om je aanpak te herzien.
Onderzoek van Aether Agency (2026) laat zien dat 78% van Perplexity-citaties afkomstig is van content die in de afgelopen 12 maanden gepubliceerd of bijgewerkt werd. En uit analyse van platformgedrag blijkt dat content binnen 2 tot 3 maanden na publicatie begint te vervallen als het niet wordt bijgewerkt of aangehaald door andere bronnen.
Wat dit betekent voor je aanpak: publiceren en vergeten werkt niet meer. Wie vindbaar wil zijn in Perplexity, heeft een actieve updatekalender nodig, niet per se meer nieuwe artikelen. Kies je best presterende pagina's, update ze per kwartaal met actuele data en nieuwe voorbeelden, en voeg een zichtbare "Bijgewerkt op"-datum toe in de HTML. Perplexity's crawler leest dat als verssignaal.
Dit is ook de reden waarom een recent persartikel over jouw bedrijf soms meer citaties oplevert dan je eigen content: nieuwsbronnen worden structureel als actueel herkend. Dat is een inzicht dat direct richting geeft aan waar je energie in steekt.
LinkedIn is plotseling je krachtigste tool voor Perplexity-citaties
Tussen november 2025 en februari 2026 steeg LinkedIn van buiten de top 20 naar de meest geciteerde bron bij professionele vragen op alle grote AI-zoekmachines. Dat is geen toeval en geen tijdelijk fenomeen: LinkedIn valt precies in de categorie trust seeds die Perplexity als gezaghebbend classificeert.
Voor Nederlandse ondernemers en marketeers is dit een praktisch inzicht. Je hoeft niet per se meer blogartikelen te schrijven, je moet zichtbaar zijn op de platforms die Perplexity vertrouwt. Een compleet en actueel LinkedIn-profiel, een bedrijfspagina met recente posts, aanwezigheid op brancheplatforms en reviews op erkende vergelijkers: dat zijn de touchpoints die het systeem herkent als extern bewijs van expertise.
Hetzelfde geldt voor earned media. Een vermelding in een vakpublicatie of nieuwssite weegt zwaarder dan tien eigen blogposts op je eigen domein, omdat Perplexity journalistieke bronnen structureel bevoordeelt vanwege de redactionele filters die ze doorlopen hebben. Een perspublicatie is dus niet alleen PR, het is een rankingsignaal voor GEO en AEO.
De bredere les: AI-vindbaarheid is niet alleen een kwestie van wat er op je eigen site staat. Het ecosysteem rondom je merk, je vermeldingen, je platform-aanwezigheid, vormt het frame waarbinnen AI antwoorden geeft. Wie dat alleen via de eigen site probeert op te lossen, mist de helft van het spel.
Wat Perplexity technisch leest op jouw site, en wat de meeste sites missen
Perplexity heeft een eigen crawler genaamd PerplexityBot. Die bezoekt je site, leest de content en slaat relevante informatie op in de index die het systeem gebruikt voor antwoorden. Naast reguliere HTML leest Perplexity ook twee soorten gestructureerde signalen die de meeste sites simpelweg niet bieden.
Het eerste is een llms.txt-bestand: een gestructureerde tekst in de root van je site die AI-systemen vertelt hoe jouw site werkt, welke pagina's het belangrijkst zijn en welke content je beschikbaar stelt. Uit ons eigen onderzoek onder de 500 populairste Nederlandse domeinen blijkt dat slechts 7% zo'n bestand heeft. Vrijwel niemand is dus al bewust bezig met hoe AI-systemen hun site lezen, en dat is een opening voor wie dat wel doet. Tools als Claude kunnen je helpen zo'n bestand in enkele minuten op te stellen op basis van een beschrijving van je bedrijf.
Het tweede is FAQ-schema: structured data in JSON-LD die vragen en antwoorden expliciet markeert, zodat Perplexity directe, machineleesbare antwoorden heeft zonder te raden. Uit hetzelfde Writgo-onderzoek had slechts 1,5% van de bereikbare NL-sites FAQ-schema op de homepage. Dat zijn de pagina's die Perplexity het makkelijkst kan citeren, en bijna niemand benut die kans.
Wil je weten hoe geciteerbaar jouw site nu is? De gratis AI-citatie-check geeft je een score van 0 tot 100 op de factoren die AI-assistenten meten. Van de 26 Nederlandse sites die de check al deden, is de gemiddelde score 53 van de 100.
Controleer eerst of Perplexity je al citeert: zoek op Perplexity.ai naar de vraag die jouw klant stelt en kijk of jouw site in de bronnen verschijnt. Staat een concurrent er wel en jij niet, dan weet je precies waar de prioriteit ligt.
De crawl-controverse die niemand hardop bespreekt
In augustus 2025 publiceerde Cloudflare een onderzoek waaruit bleek dat Perplexity hun crawler actief vermomde. Wanneer sites PerplexityBot blokkeerden in robots.txt of via firewallregels, schakelde het systeem over op een nep-user-agent die zich voordeed als een gewone Chrome-browser op macOS. Malwarebytes documenteerde dat Perplexity IP-adressen en netwerken rouleerde om detectie te omzeilen, met activiteit die tienduizenden domeinen bestreek.
De implicatie is tweeledig. Als je Perplexity blokkeert in robots.txt, is de kans reëel dat je content toch wordt gelezen, maar dat je geen invloed hebt op hoe. Je verdwijnt uit de geciteerde bronnen terwijl het systeem je content mogelijk als achtergrondinformatie blijft gebruiken. Als je Perplexity juist wél toelaat en je content optimaliseert voor citaties, heb je de meeste controle over het resultaat.
Voor verreweg de meeste mkb-bedrijven is blokkeren onverstandig. Je hebt geen licentiebelangen te beschermen zoals grote uitgevers dat doen. Blokkeren betekent dat je geen citatieplek claimt op een platform met 100 miljoen gebruikers, terwijl de crawler jouw site mogelijk toch leest via vermomd verkeer. Dat is de slechtste verhouding: geen zichtbaarheid, geen controle.
Nieuwsmedia en uitgevers met strikte contentlicenties staan hier anders in: voor hen kan bewuste uitsluiting onderdeel zijn van een onderhandelingsstrategie over licentievergoedingen. Maar voor een adviesbureau, SaaS-product of webwinkel is er geen rationele reden om Perplexity buiten de deur te houden.
Zo pak je Perplexity-optimalisatie aan zonder je hele contentstrategie om te gooien
De meeste winst zit niet in een nieuw contentplan maar in gerichte aanpassingen op wat je al hebt. Hier zijn de stappen in volgorde van impact.
- Controleer robots.txt. Staat PerplexityBot niet geblokkeerd? Goed. Voeg anders expliciet
User-agent: PerplexityBottoe metAllow: /. - Maak een llms.txt. Zet in de root van je site een tekstbestand met een korte beschrijving van je bedrijf, je kernpagina's en wat je aanbiedt. Zie het als een visitekaartje specifiek voor AI-crawlers.
- Voeg FAQ-schema toe op je beste pagina's. Slechts 1,5% van de Nederlandse topsites doet dit al. Markeer vragen en antwoorden in JSON-LD, zodat Perplexity directe antwoorden kan citeren zonder te interpreteren.
- Update bestaande content actief. Voeg actuele data en statistieken toe, zet een zichtbare bijgewerkte datum, en schrijf pagina's met directe antwoorden op de vraag die je wil bezitten.
- Bouw aanwezigheid op trust seeds. Zorg dat je LinkedIn-profiel en bedrijfspagina compleet en actueel zijn. Zoek naar vermeldingen op vakplatforms, reviews en branchesites die Perplexity als betrouwbaar herkent.
- Streef naar earned media. Eén vermelding in een sectorpublicatie weegt als rankingsignaal zwaarder dan tien eigen blogposts voor Perplexity-citaties.
| Factor | Google SEO | Perplexity-citatie |
|---|---|---|
| Versheid content | Matig relevant | Dominant (44,2%) |
| Backlinks | Hoog gewicht | Indirect via domeinautoriteit |
| Structured data / FAQ-schema | Helpend | Sterk directe citeerbaar |
| Platformaanwezigheid (LinkedIn, Reddit) | Laag gewicht | Hoog via trust seeds |
| Eigen domein vs. earned media | Eigen domein centraal | Earned media structureel bevoordeeld |
Onze kijk op Perplexity-optimalisatie
Wij zien bij de sites die wij beheren dat Perplexity-citaties geen kwestie zijn van geluk maar van citeerbaarheid. Het meest voorkomende probleem is niet dat een site slecht is, maar dat hij op de verkeerde manier is ingericht voor AI-lezers: dunne pagina's zonder directe antwoorden, geen structured data, geen llms.txt, en geen externe aanwezigheid op de platforms die Perplexity vertrouwt.
We zien ook dat ondernemers hun strategie te snel bouwen rond één specifiek platform. Perplexity vandaag, iets nieuws over zes maanden. Wie zijn aanpak vastschroeft aan één AI-tool bouwt op zand. De methode moet kloppen: antwoordgerichte content, aantoonbare expertise, externe vermeldingen. Dat werkt voor Google AI Overviews, voor Perplexity en voor welk AI-antwoordsysteem er ook dominant wordt.
Dat Perplexity met 44,2% versheidsgewicht zo sterk op actualiteit leunt, is een kans voor kleinere spelers. Je hoeft geen Wikipedia-domeinautoriteit te hebben: je hebt het meest actuele en directe antwoord nodig op precies die vraag. Dat is iets wat mkb-bedrijven zelf in handen hebben, mits ze ophouden met publiceren-en-vergeten.
Wat we niet doen: beweren dat jouw site nu niet wordt geciteerd. Dat weten we niet zonder te meten. Wat we wel weten op basis van eigen data: van de 26 Nederlandse sites die onze gratis AI-citatie-check deden, is de gemiddelde score 53 van de 100. Er is structureel ruimte voor verbetering bij de meeste ondernemers. Één pagina met echte data en een duidelijk antwoord doet meer dan honderd dunne blogjes. Dat is geen mening, dat is wat wij dagelijks meten op de 15+ sites die wij zelf beheren.
Bronnen
- Perplexity AI Statistics 2026 - DemandSage
- 12 Proven Tactics to Rank Higher on Perplexity AI in 2026 - Nick Lafferty
- How Perplexity Selects Sources: Inside the Algorithm - AuthorityTech
- How Perplexity Selects Sources - Aether Agency (2026)
- Perplexity AI ignores no-crawling rules on websites - Malwarebytes
- How Perplexity AI Answers Work - ZipTie.dev
- AI Search vs Traditional Clicks - Passionfruit
Wat is het verschil tussen Perplexity en Google?
Perplexity geeft één samengesteld antwoord met 3 tot 4 expliciete bronvermeldingen; Google toont een lijst van links. Je optimaliseert bij Perplexity voor citaties, niet voor klikposities.
Hoe weet ik of Perplexity mijn site al citeert?
Zoek op Perplexity.ai naar de vraag die jouw klant stelt en kijk of jouw domein in de bronnen verschijnt. Voor een bredere meting kun je de gratis AI-citatie-check doen.
Moet ik Perplexity apart optimaliseren naast Google?
Niet volledig apart: antwoordgerichte content, actuele data en externe vermeldingen helpen bij beide. Het verschil zit in versheid (veel zwaarder bij Perplexity) en platformaanwezigheid (trust seeds tellen bij Perplexity, niet bij Google).
Werkt FAQ-schema ook voor Perplexity-citaties?
Ja. Structured data in JSON-LD geeft Perplexity directe, machineleesbare antwoorden die het kan citeren zonder te interpreteren. Slechts 1,5% van de Nederlandse topsites gebruikt dit al.
Wat is een llms.txt en heb ik dat nodig?
Een llms.txt is een tekstbestand in de root van je site dat AI-systemen vertelt welke pagina's belangrijk zijn en wat je bedrijf doet. Slechts 7% van de populairste NL-sites heeft er een, maar het is in een uur te maken.
Hoe snel werkt een update van content door in Perplexity?
Perplexity crawlt actief en verwerkt verse content snel, soms binnen dagen. Voor actuele onderwerpen compresseert het versheidsvenster zelfs naar 48 tot 72 uur, blijkt uit platformanalyse.
Begin met meten, dan pas met aanpassen
De cijfers zijn duidelijk: 780 miljoen zoekopdrachten per maand, 44,2% versheidsgewicht, 7% van de NL-sites met een llms.txt. Maar of dit voor jouw situatie relevant is, weet je pas als je meet. Doe de gratis AI-citatie-check om te zien hoe geciteerbaar jouw site nu is, en bekijk de toolkit voor de tools en sjablonen die wij zelf gebruiken op onze eigen sites. Theorie zonder meting telt niet: begin met weten waar je staat.


